celery란?
📘celery
worker
-
싱글스레드 기반으로 작동하는 javascript는 싱글스레드의 단점을 보완하기 위해 코드들이 비동기로 실행된다. 그러나 API비동기 실행이 너무 많이 쌓이게 되면 모든 작업의 실행 속도가 느려질 수 있다. 이 문제를 해결하기 위해 나온 것이 바로 워커(Worker) 이다. 웹 워커 API가 멀티 스레딩을 지원하게 되어 워커를 이용하면 워커에서 작성된 스크립트는 메인 스레드에서 분기되어 독립된 스레드로 실행되기 때문에 메모리 자원을 효율적으로 사용할 수 있다.
-
Celery는 Python으로 작성된 비동기 작업 큐(Asynchronous task queue/job queue)입니다. 앞서 소개한 작업(Task)를 브로커(Broker, 스포카 서버는 Redis를 사용)를 통해 전달하면 하나 이상의 워커(Worker)가 이를 처리하는 구조입니다. 포인트 적립-공유에 따른 분배처리, 포스팅 기능, 페이스북/트위터 공유등의 비동기 처리가 필요한 작업을 Celery에 위임하여 처리하고 있습니다.
Celey
-
사용자에게 즉각적인 반응을 보여줄 필요가 없는 작업들로 인해 사용자가 느끼는 Deley 를 최소하 화기 위해 사용 된다.
-
Celery는 task를 broker를 통해 전달하고 worker가 처리하는 구조입니다.
-
장고에서 발생한 요청을 message broker가 받아 워커(celery)를 이용하여 분산처리한다
Celery 동작구조
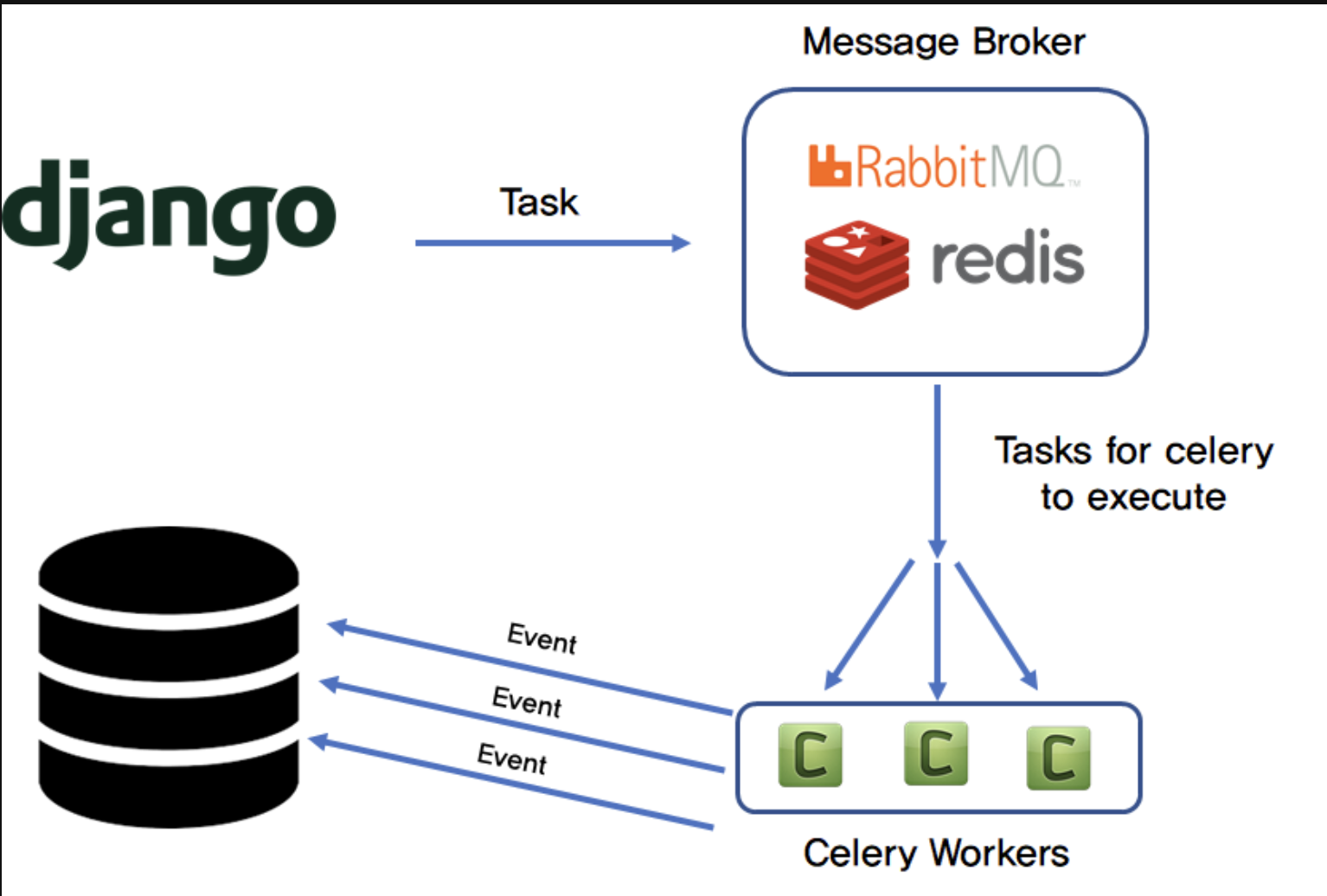
-Celery의 동작 구조이다. 웹 서비스(Django)에서 발생한 요청(Task)를 Message Broker에서 받아 Celery를 이용하여 분산 처리를 진행한다. Celery에서는 작업이 완료되는 (특정 이벤트)에 DB Task를 수행한다.
Celery 쓰는이유
- 예를 들어 회원 가입 축하 이메일 발송, 어드민 주문내역 엑셀 다운로드 같은 기능이 해당된다. 이 API 에 포함된 외부 연동이나 무거운 작업들은 Celery Task로 정의해서 브로커(RabbitMQ)와 컨슈머(Celery Worker)를 이용해 비동기로 처리함으로써 사용자에게 가능한 빠른 응답 결과를 제공할 수 있을 것이다.
작업 결과 보관하기 (Result Backend)
- Celery는 Task 작업 결과를 저장하기 위한 여러가지 result backend 를 내장하고 있다. (예: SQLAlchemy, Django, Memcached, RabbitMq, Redis, RPC 등등) result backend 를 지정하려면 Celery 인스턴스에 backend 키워드 인자를 추가한다. rpc 를 result backend 로 지정할 경우 작업 결과를 임시 AMQP 메시지로 다시 돌려보내는 방식으로 동작하고, 작업 결과로 반환된 AsyncResult 인스턴스를 유지할 수 있게 된다.
celery 설정
- celery.py
celery.py 안에 app =Celery(파일이름,broker=브로커설,backend=백엔드설,include=
[파일이름.tasks]) @app.task- tasts.py파일안에
@app.task밑에 함수 구현
- tasts.py파일안에
- 해당 파일에서 쓸부분에 구현한함수.deley
요약해서 쓴것이므로 깃에서 코드 참고할것
Celery 워커 실행법
celery -A (파일이름) worker –loglevel=info